
“Siri, Read My Mind”: A New Device Lets Users Think Commands
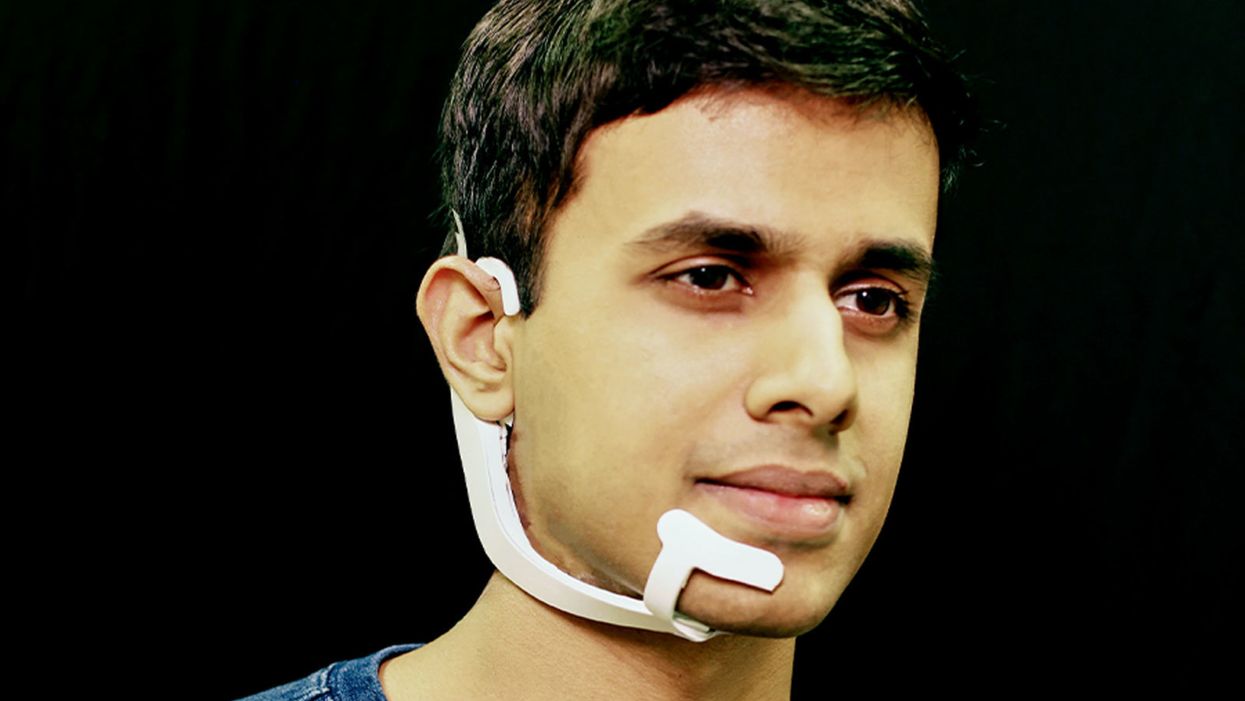
Arnav Kapur, a researcher in the Fluid Interfaces Group at MIT, wears an earlier prototype of the AlterEgo. A newer version is more discreet.
Sometime in the near future, we won't need to type on a smartphone or computer to silently communicate our thoughts to others.
"We're moving as fast as possible to get the technology right, to get the ethics right, to get everything right."
In fact, the devices themselves will quietly understand our intentions and express them to other people. We won't even need to move our mouths.
That "sometime in the near future" is now.
At the recent TED Conference, MIT student and TED Fellow Arnav Kapur was onstage with a colleague doing the first live public demo of his new technology. He was showing how you can communicate with a computer using signals from your brain. The usually cool, erudite audience seemed a little uncomfortable.
"If you look at the history of computing, we've always treated computers as external devices that compute and act on our behalf," Kapur said. "What I want to do is I want to weave computing, AI and Internet as part of us."
His colleague started up a device called AlterEgo. Thin like a sticker, AlterEgo picks up signals in the mouth cavity. It recognizes the intended speech and processes it through the built-in AI. The device then gives feedback to the user directly through bone conduction: It vibrates your inner ear drum and gives you a response meshing with your normal hearing.
Onstage, the assistant quietly thought of a question: "What is the weather in Vancouver?" Seconds later, AlterEgo told him in his ear. "It's 50 degrees and rainy here in Vancouver," the assistant announced.
AlterEgo essentially gives you a built-in Siri.
"We don't have a deadline [to go to market], but we're moving as fast as possible to get the technology right, to get the ethics right, to get everything right," Kapur told me after the talk. "We're developing it both as a general purpose computer interface and [in specific instances] like on the clinical side or even in people's homes."
Nearly-telepathic communication actually makes sense now. About ten years ago, the Apple iPhone replaced the ubiquitous cell phone keyboard with a blank touchscreen. A few years later, Google Glass put computer screens into a simple lens. More recently, Amazon Alexa and Microsoft Cortana have dropped the screen and gone straight for voice control. Now those voices are getting closer to our minds and may even become indistinguishable in the future.
"We knew the voice market was growing, like with getting map locations, and audio is the next frontier of user interfaces," says Dr. Rupal Patel, Founder and CEO of VocalID. The startup literally gives voices to the voiceless, particularly people unable to speak because of illness or other circumstances.
"We start with [our database of] human voices, then train our deep learning technology to learn the pattern of speech… We mix voices together from our voice bank, so it's not just Damon's voice, but three or five voices. They are different enough to blend it into a voice that does not exist today – kind of like a face morph."
The VocalID customer then has a voice as unique as he or she is, mixed together like a Sauvignon blend. It is a surrogate voice for those of us who cannot speak, just as much as AlterEgo is a surrogate companion for our brains.
"I'm very skeptical keyboards or voice-based communication will be replaced any time soon."
Voice equality will become increasingly important as Siri, Alexa and voice-based interfaces become the dominant communication method.
It may feel odd to view your voice as a privilege, but as the world becomes more voice-activated, there will be a wider gap between the speakers and the voiceless. Picture going shopping without access to the Internet or trying to eat healthily when your neighborhood is a food desert. And suffering from vocal difficulties is more common than you might think. In fact, according to government statistics, around 7.5 million people in the U.S. have trouble using their voices.
While voice communication appears to be here to stay, at least for now, a more radical shift to mind-controlled communication is not necessarily inevitable. Tech futurist Wagner James Au, for one, is dubious.
"I'm very skeptical keyboards or voice-based communication will be replaced any time soon. Generation Z has grown up with smartphones and games like Fortnite, so I don't see them quickly switching to a new form factor. It's still unclear if even head-mounted AR/VR displays will see mass adoption, and mind-reading devices are a far greater physical imposition on the user."
How adopters use the newest brain impulse-reading, voice-altering technology is a much more complicated discussion. This spring, a video showed U.S. House Speaker Nancy Pelosi stammering and slurring her words at a press conference. The problem is that it didn't really happen: the video was manufactured and heavily altered from the original source material.
So-called deepfake videos use computer algorithms to capture the visual and vocal cues of an individual, and then the creator can manipulate it to say whatever it wants. Deepfakes have already created false narratives in the political and media systems – and these are only videos. Newer tech is making the barrier between tech and our brains, if not our entire identity, even thinner.
"Last year," says Patel of VocalID, "we did penetration testing with our voices on banks that use voice control – and our generation 4 system is even tricky for you and me to identify the difference (between real and fake). As a forward-thinking company, we want to prevent risk early on by watermarking voices, creating a detector of false voices, and so on." She adds, "The line will become more blurred over time."
Onstage at TED, Kapur reassured the audience about who would be in the driver's seat. "This is why we designed the system to deliberately record from the peripheral nervous system, which is why the control in all situations resides with the user."
And, like many creators, he quickly shifted back to the possibilities. "What could the implications of something like this be? Imagine perfectly memorizing things, where you perfectly record information that you silently speak, and then hear them later when you want to, internally searching for information, crunching numbers at speeds computers do, silently texting other people."
"The potential," he concluded, "could be far-reaching."
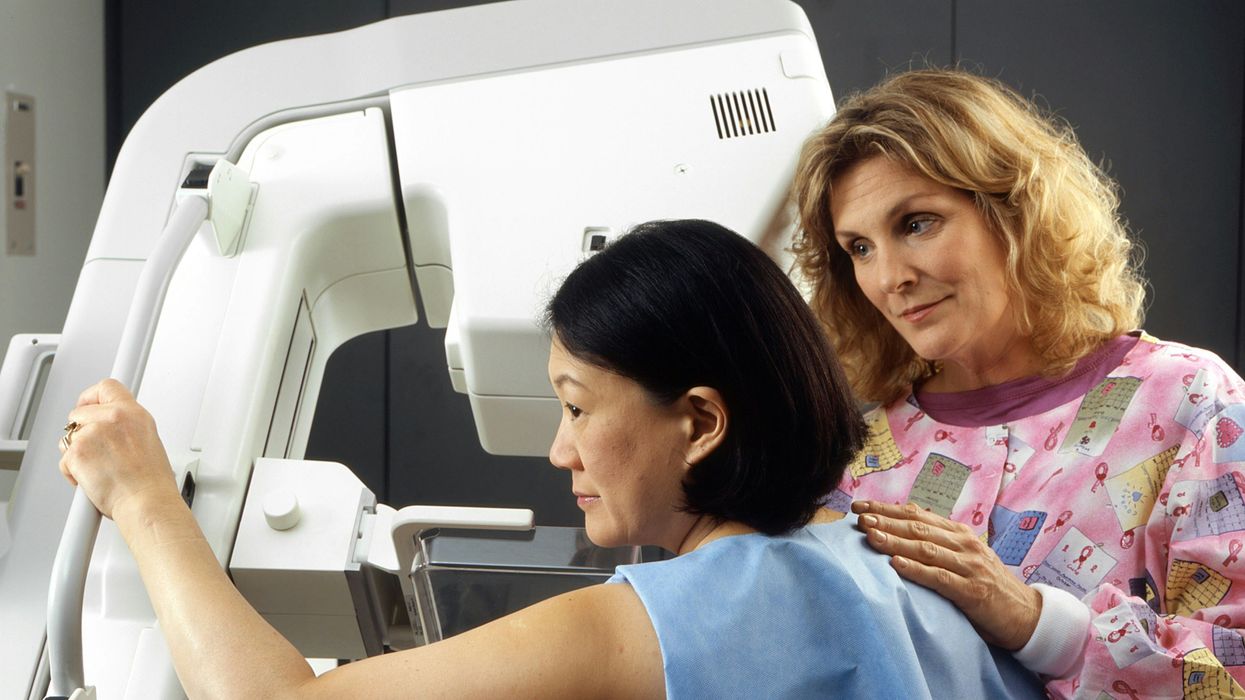
A woman receives a mammogram, which can detect the presence of tumors in a patient's breast.
When a patient is diagnosed with early-stage breast cancer, having surgery to remove the tumor is considered the standard of care. But what happens when a patient can’t have surgery?
Whether it’s due to high blood pressure, advanced age, heart issues, or other reasons, some breast cancer patients don’t qualify for a lumpectomy—one of the most common treatment options for early-stage breast cancer. A lumpectomy surgically removes the tumor while keeping the patient’s breast intact, while a mastectomy removes the entire breast and nearby lymph nodes.
Fortunately, a new technique called cryoablation is now available for breast cancer patients who either aren’t candidates for surgery or don’t feel comfortable undergoing a surgical procedure. With cryoablation, doctors use an ultrasound or CT scan to locate any tumors inside the patient’s breast. They then insert small, needle-like probes into the patient's breast which create an “ice ball” that surrounds the tumor and kills the cancer cells.
Cryoablation has been used for decades to treat cancers of the kidneys and liver—but only in the past few years have doctors been able to use the procedure to treat breast cancer patients. And while clinical trials have shown that cryoablation works for tumors smaller than 1.5 centimeters, a recent clinical trial at Memorial Sloan Kettering Cancer Center in New York has shown that it can work for larger tumors, too.
In this study, doctors performed cryoablation on patients whose tumors were, on average, 2.5 centimeters. The cryoablation procedure lasted for about 30 minutes, and patients were able to go home on the same day following treatment. Doctors then followed up with the patients after 16 months. In the follow-up, doctors found the recurrence rate for tumors after using cryoablation was only 10 percent.
For patients who don’t qualify for surgery, radiation and hormonal therapy is typically used to treat tumors. However, said Yolanda Brice, M.D., an interventional radiologist at Memorial Sloan Kettering Cancer Center, “when treated with only radiation and hormonal therapy, the tumors will eventually return.” Cryotherapy, Brice said, could be a more effective way to treat cancer for patients who can’t have surgery.
“The fact that we only saw a 10 percent recurrence rate in our study is incredibly promising,” she said.

Urinary tract infections account for more than 8 million trips to the doctor each year.
Few things are more painful than a urinary tract infection (UTI). Common in men and women, these infections account for more than 8 million trips to the doctor each year and can cause an array of uncomfortable symptoms, from a burning feeling during urination to fever, vomiting, and chills. For an unlucky few, UTIs can be chronic—meaning that, despite treatment, they just keep coming back.
But new research, presented at the European Association of Urology (EAU) Congress in Paris this week, brings some hope to people who suffer from UTIs.
Clinicians from the Royal Berkshire Hospital presented the results of a long-term, nine-year clinical trial where 89 men and women who suffered from recurrent UTIs were given an oral vaccine called MV140, designed to prevent the infections. Every day for three months, the participants were given two sprays of the vaccine (flavored to taste like pineapple) and then followed over the course of nine years. Clinicians analyzed medical records and asked the study participants about symptoms to check whether any experienced UTIs or had any adverse reactions from taking the vaccine.
The results showed that across nine years, 48 of the participants (about 54%) remained completely infection-free. On average, the study participants remained infection free for 54.7 months—four and a half years.
“While we need to be pragmatic, this vaccine is a potential breakthrough in preventing UTIs and could offer a safe and effective alternative to conventional treatments,” said Gernot Bonita, Professor of Urology at the Alta Bro Medical Centre for Urology in Switzerland, who is also the EAU Chairman of Guidelines on Urological Infections.
The news comes as a relief not only for people who suffer chronic UTIs, but also to doctors who have seen an uptick in antibiotic-resistant UTIs in the past several years. Because UTIs usually require antibiotics, patients run the risk of developing a resistance to the antibiotics, making infections more difficult to treat. A preventative vaccine could mean less infections, less antibiotics, and less drug resistance overall.
“Many of our participants told us that having the vaccine restored their quality of life,” said Dr. Bob Yang, Consultant Urologist at the Royal Berkshire NHS Foundation Trust, who helped lead the research. “While we’re yet to look at the effect of this vaccine in different patient groups, this follow-up data suggests it could be a game-changer for UTI prevention if it’s offered widely, reducing the need for antibiotic treatments.”